# 点估计
设总体 X 的分布函数形式已知,但它的一个或多个参数未知,借助于总体 X 的一个样本来估计总体未知参数的值的问题称为参数的点估计问题。
# 矩估计法
样本矩
Al=n1i=1∑nXil,l=1,2,⋯,k.
总体矩
μl=E(Xl)={∫−∞∞xlf(x;θ1,θ2,⋯,θk)dx∑xlp(x;θ1,θ2,⋯,θk)X为连续型,X为离散型.
可以用样本矩作为相应的总体矩的估计量。设(有多少个需要估计的参数就列多少个方程)
⎩⎪⎪⎪⎪⎨⎪⎪⎪⎪⎧μ1=E(X)=μ1(θ1,θ2,⋯,θk),μ2=E(X2)=D(X)+[E(X)]2=μ2(θ1,θ2,⋯,θk)⋯ ⋯ ⋯μk=μk(θ1,θ2,⋯,θk)
由上述方程组解出 θ1,θ2,⋯,θk (用 μ1,μ2,⋯,μk 表示),然后用 A1,A2,⋯,Ak 替换 μ1,μ2,⋯,μk 即得总体分布中未知参数的矩估计量。
常用结论: A1=Xˉ,A2−A1=n1∑i=1nXi2−Xˉ2=n1∑i=1n(Xi−Xˉ)2
# 最大似然估计
若总体 X 为离散型, X1,X2,⋯,Xn 是来自 X 的样本,对应的观察值为 x1,x2,⋯,xn ,则这组样本取到这组对应观察值的概率为
L(θ)=L(x1,x2,⋯,xn;θ)=i=1∏np(xi;θ)
其中, θ 是总体 X 的参数, p(xi;θ) 是 X 的概率密度函数, L(θ) 称为样本的似然函数, θ 是未知参数。一个直观的想法是,我们已经观察到样本取到 x1,x2,⋯,xn 这组观察值,那么使这组观察值出现的概率最大的 θ 就是我们要求的参数估计,记为 θ^ 。这种方法称为最大似然估计法。
若总体 X 为连续型,似然函数变为
L(θ)=L(x1,x2,⋯,xn;θ)=i=1∏nf(xi;θ)
两者都只要从方程
dθdlnL(θ)=0
中解出 θ 即可。
最大似然估计的核心思想是求使得当前观测值出现的概率最大时对应的参数值。
# 估计量的标准
- 无偏性: E(θ^)=θ ,即估计量的数学期望等于真实参数值。PS:任意阶样本矩都是总体矩的无偏估计量。
- 有效性: 对 θ 的两个无偏估计量 θ^1,θ^2 ,若 D(θ^1)≤D(θ^2) ,则称 θ^1 更有效。
- 相合性: 若 θ 的估计量 θ^ 当样本容量 n→∞ 时收敛于 θ ,则称 θ^ 为 θ 的相合估计量。
# 区间估计
对于给定的显著性水平 α(0<α<1) ,若由来自样本 X1,X2,⋯,Xn 确定的统计量 θ1,θ2 ,使得
P(θ1<θ<θ2)=1−α
则称 (θ1,θ2) 为总体参数 θ 的 置信水平为 1−α 的置信区间, 1−α 为置信水平。其核心思想是多次抽样得到的多个区间中,包含总体参数 θ 真值的区间数量占总区间数量的比例为 1−α ,或每次抽样得到的区间包含 θ 真值的概率为 1−α 。

补充:二项分布 B(n,p) 总体对 p 的区间估计为 (p^±Z2αnp^(1−p^)) 。
# 假设检验
基本思想:对总体的参数作出假设,然后通过抽样进行统计分析,从而判断假设是否成立。弃真错误的概率为 α 。
提出无效假设 / 反假设(Null Hypothesis, H0 )和备择假设(Alternative Hypothesis, H1 ),单边( θ=θ0 )还是双边( θ<θ0 或 θ>θ0 ),选定显著性水平 α 。
# 正态总体

# 二项总体
单个总体检验:
检验统计量 Z=np^(1−p^)p^−p0 , p0 为假设的总体比例, n 为样本容量, p^ 为样本比例。
| H0 | H1 | 拒绝域 |
|---|
| p=p0 | p=p0 | ∥z∥>Z2α |
| p≤p0 | p>p0 | z>Zα |
| p≥p0 | p<p0 | z<−Zα |
| 2. 两个总体检验: | | |
检验统计量 Z=p^(1−p^)(n11+n21)p^1−p^2 ,其中 p^=n1+n2x1+x2 ,x1,x2 为关注样本的频数, p^1,p^2 分别为两个样本比例, n1,n2 分别为两个样本容量。
| H0 | H1 | 拒绝域 |
|---|
| p1=p2 | p1=p2 | ∥z∥>Z2α |
| p1≤p2 | p1>p2 | z>Zα |
| p1≥p2 | p1<p2 | z<−Zα |
# 卡方列联表
| 1 | 1 | 2 | ⋯ | j | ⋯ | Total |
|---|
| 1 | n11 | n12 | ⋯ | n1j | ⋯ | n1⋅ |
| 2 | n21 | n22 | ⋯ | n2j | ⋯ | n2⋅ |
| ⋮ | ⋮ | ⋮ | ⋮ | ⋮ | ⋮ | ⋮ |
| i | ni1 | ni2 | ⋯ | nij | ⋯ | ni⋅ |
| ⋮ | ⋮ | ⋮ | ⋮ | ⋮ | ⋮ | ⋮ |
| Total | n⋅1 | n⋅2 | ⋯ | n⋅j | ⋯ | n |
χ2=i=1∑rj=1∑cnni⋅n⋅j(nij−nni⋅n⋅j)
其中 r,c 分别为行数和列数。当 χ2≥χα2((r−1)(c−1)) 时,拒绝 H0 ,否则接受 H0 。
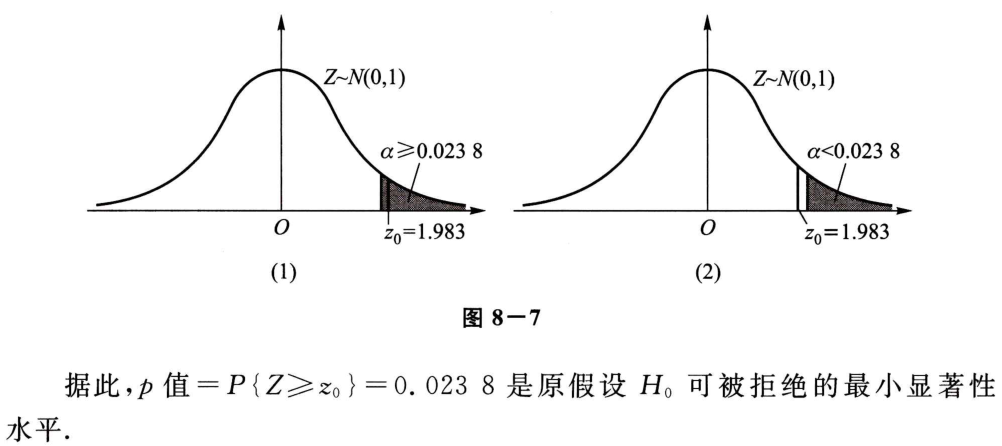
# p 值法
假设检验问题的 p 值是由检验统计量的样本观察值得出的原假设可被拒绝的最小显著性水平。若 p≤α ,则拒绝 H0 ,否则接受 H0 。
看一个例子:
![]()
![]()
参考资料:《概率论与数理统计》第五版 (盛骤等),高等教育出版社