# CPU 和 GPU 的差别
__global__ void vecAdd(double *a, double *b, double *c, int n) | |
{ | |
// Get our global thread ID | |
int id = blockIdx.x * blockDim.x + threadIdx.x; | |
// Make sure we do not go out of bounds | |
if (id < n) | |
c[id] = a[id] + b[id]; | |
} |
__global__表示上述程序是一个 CUDA Kernel,从 CPU 端调用并在 GPU 端执行。(called from host and excuted from device)__host__表示 CPU 端调用,CPU 端执行。__device__表示 GPU 端调用,GPU 端执行。
CPU 也可以通过堆核心达到和 GPU 相似的性能,但是这样做会导致芯片过大不经济;如果将过多核心分散在不同机器上,通信将会成为主要的开销。CPU 的访存是经过硬件电路优化的。但是 GPU 的访存更多需要程序员的干预与优化。GPU 实际上是在用并行去掩盖访存延迟。
# CUDA Interface

CUDA 提供层级化的接口用于操纵 GPU,每一个 kernel 都对应一个 thread Grid。每个 Grid 中含有多个编号 block,编号可以是一维可以是二维或其他维。每个 block 中含有若干个 thread,每个 thread 也都有对应的编号并可以修改成不同维度。追求极致的话 thread Index 一般可以设置成二维。 threadIdx.x 范围就是 [0-blockDim.x]。一个 block 中含多少个 thread 就是 blockDim.x ,一个 Grid 中含多少 block 就是 gridDim.x 。一个 kernel 的总 thread 数就是 gridDim.x * blockDim.x 。
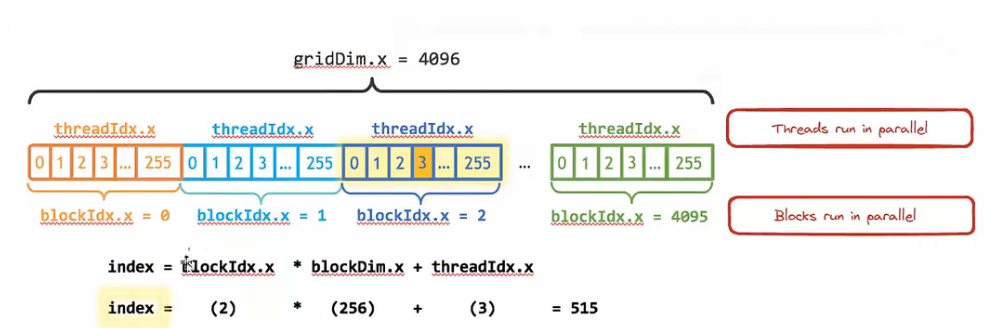
所有 block 都是并行执行的,很难控制它们执行的顺序。一个 block 中的所有 thread 也都是并行执行的。在 CUDA 中将一个 block 中的所有 thread 进行同步是一个比较常见的操作。
# GPU Hardware
为什么要这样设计?软件的层级设计和 GPU 的硬件设计是有联系的。多个 block 会被 map 到一个 SM (Streaming Multiprocessor) 上。SM 中含有多个 CUDA core,多个 thread 被 map 到 CUDA core 上。以 A100 为例,一个 SM 中含有 个执行单元。16 个核跑同一个指令。GPU 一个 SM 可以有几万个寄存器。GPU 做上下文切换速度远快于 CPU。
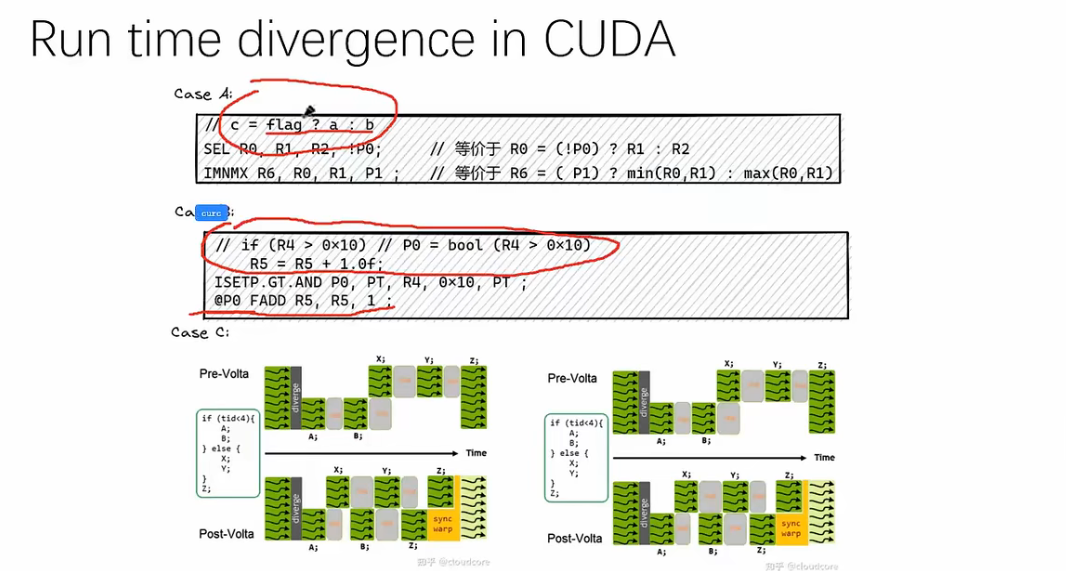
if 如果可以写成 c = flag ? a : b 或者 if (...->true) 的形式都可以很快。
# CPU-GPU Interaction
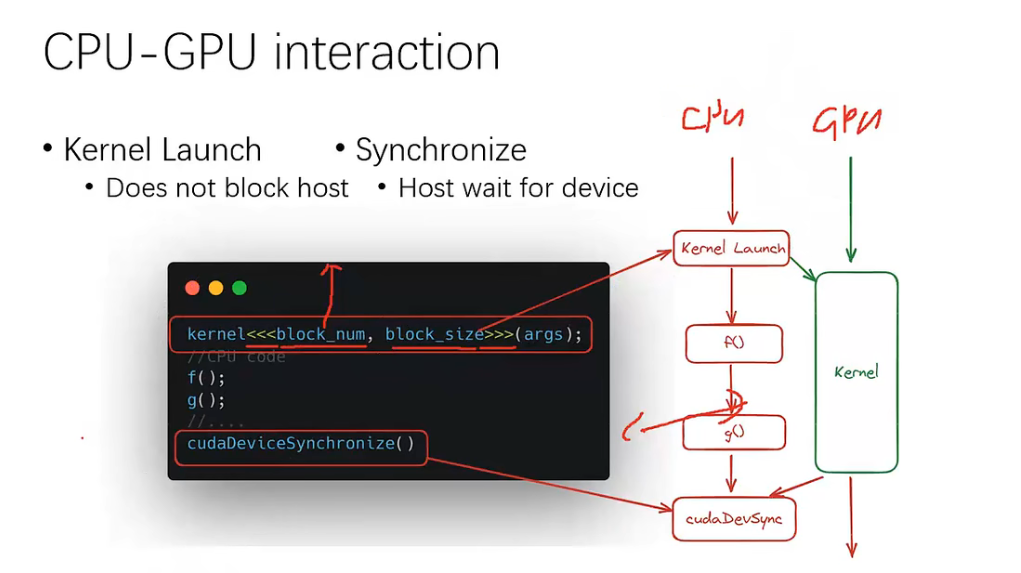
所有 kernel 启动都需要第一条语句,这条语句不是函数,只是起到一个类似于通知的作用(通知一个 kernel 的 launch)。需要显式地去让 CPU 等待 GPU 执行完成。在 launch 的同时 CPU 也可以调一些函数做自己的运算。等需要处理数据时调用 cudaDeviceSynchronize() 让 CPU 等待 GPU 将 CPU 提交的所有 kernel 执行完成。
# GPU Memory Architecture
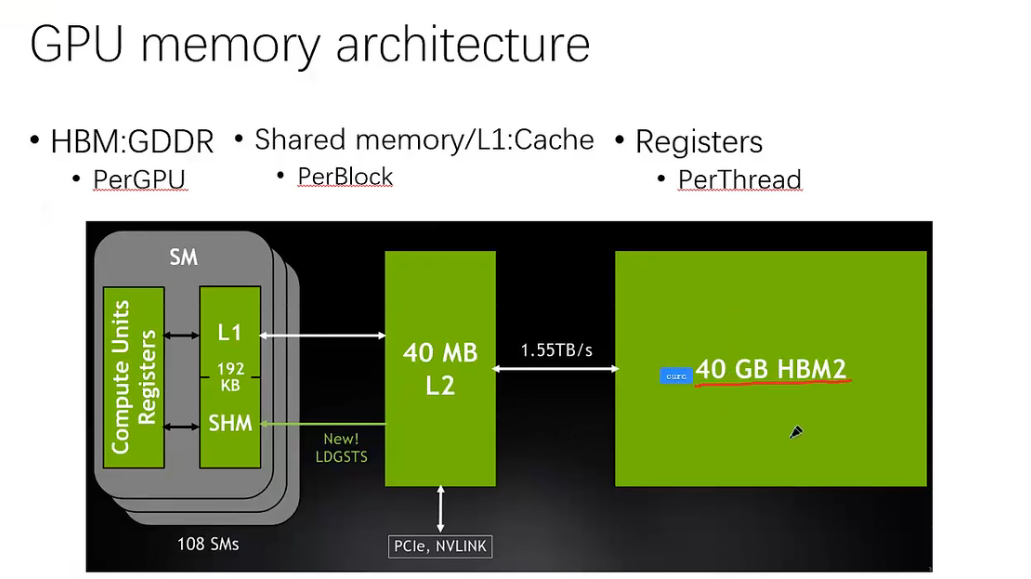
以 A100 为例,它有 40GB 的显存。显存到 L2 Cache 有 1.55TB/s。A100 中实际上有两个 L2 Cache,分为左 L2 和右 L2。L1 Cache 和 Shared Memory 共用 192KB。SHM 最大 164KB,一般设置为 48KB。
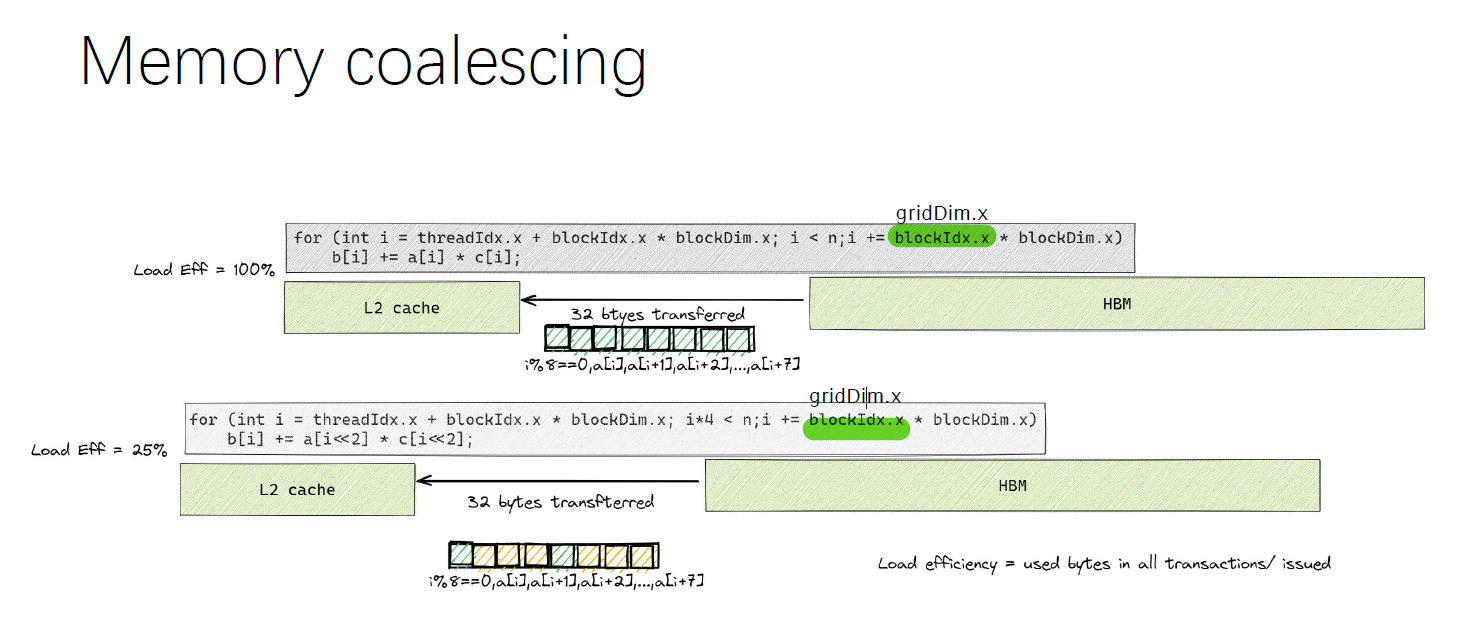
内存聚合。想要写出高性能的 GPU Code 要注意代码中的访存模式。上图中第一条代码就要快于第二条代码。一个 block 中有 256 个线程,每次循环从显存中加载 256bit(32bytes,4bytes 8)数据,第一条代码中的所有数据都被用到。第二条代码中由于只取了 i * 4 处的元素,加载的效率只有原来的 1/4。
# Banks and Shared Memory
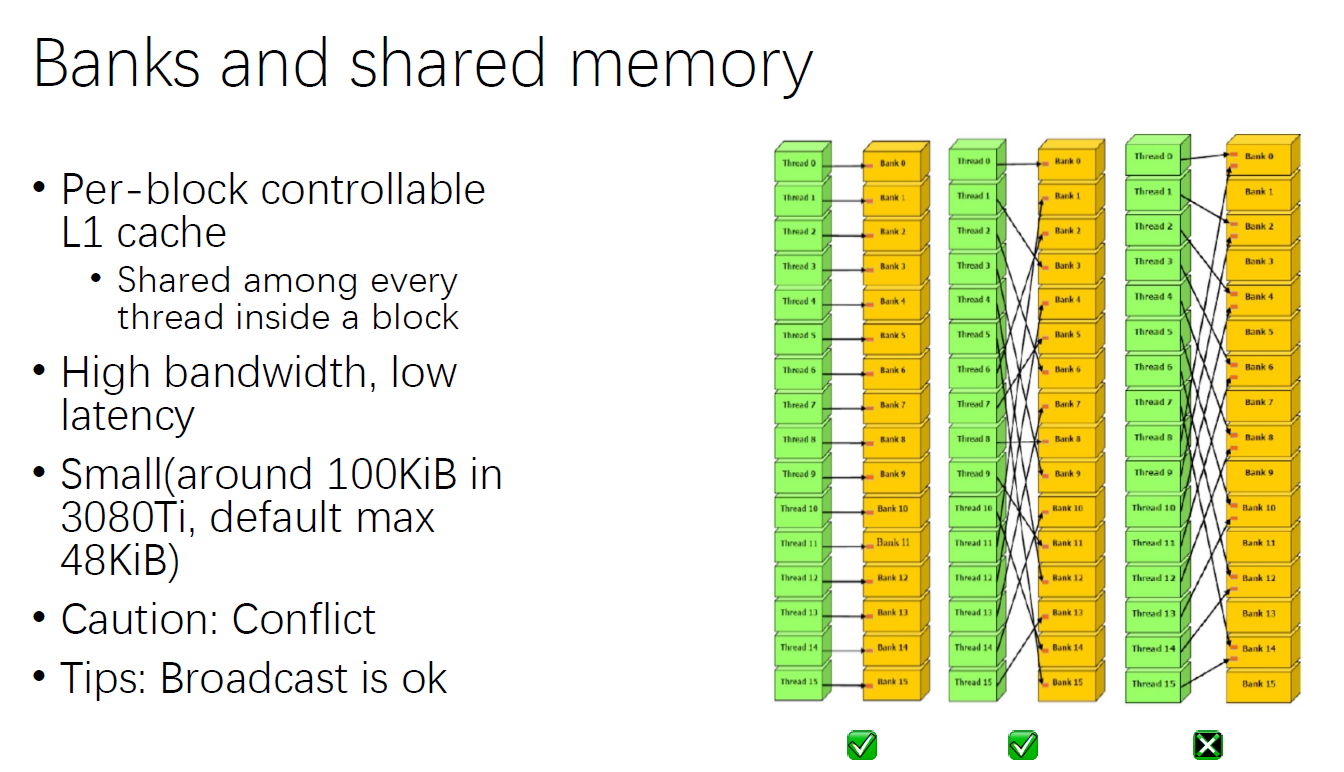
每个 block 控制一个 L1 Cache,一个 block 中的所有 thread 都可以访问到共享内存,搬运数据的流量很大,延迟很低。bank 在一个执行周期只能向一个 thread 喂数据,第三种情况程序的性能会被拖累。
# Write Correct and Efficient GPU Code

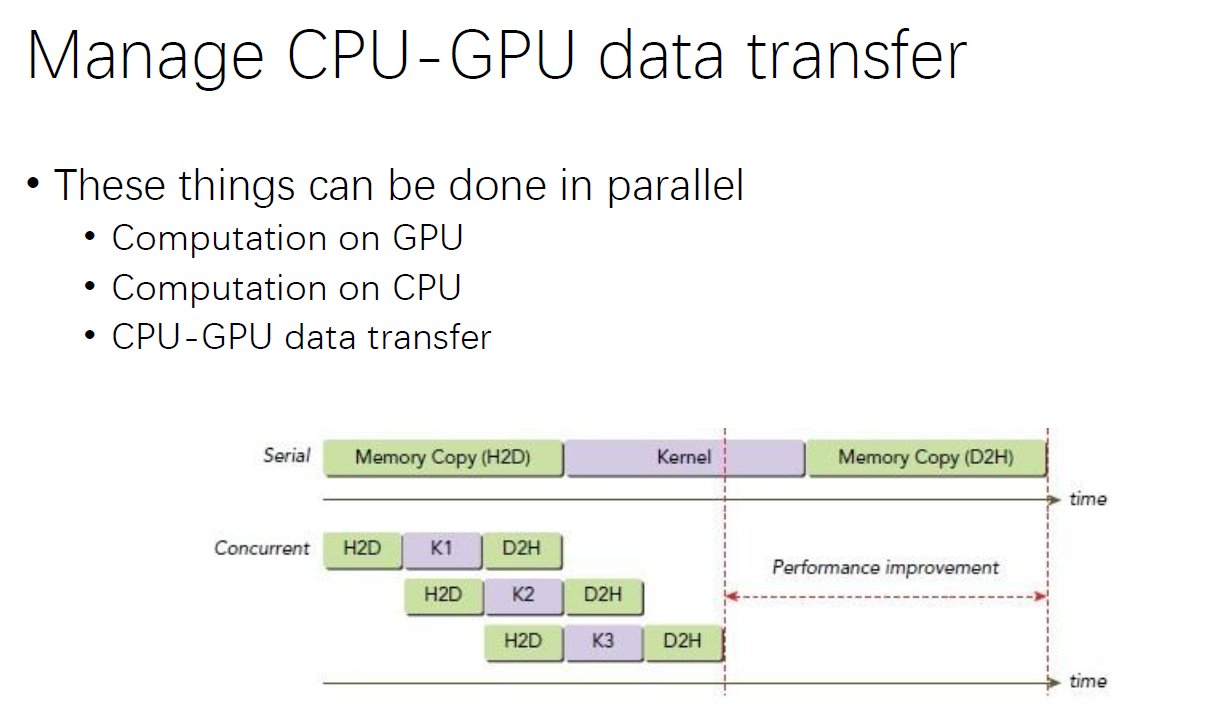
补充:第一条是 CPU-GPU 数据传输;在共享内存中使用原子操作对性能不会有较大影响。
# An Example: Histogram
# Problem Set
- array: 512MB of u_char
- bins count: 256
# CPU
void compute() | |
{ | |
for (int i = 0; i < ARRSZ; ++i) | |
++bin[arr[i]]; | |
} |
未做优化:350ms
void compute() | |
{ | |
# pragma omp parallel for num_threads(40) | |
for (int i = 0; i < ARRSZ; ++i) | |
{ | |
int c = arr[i]; | |
# pragma omp atomic | |
++bin[c]; | |
} | |
} |
负优化:6s
原因:创建了 40 个线程,每个线程都需要竞争 ++bin[c]; ,atomic 还具有一些同步的开销。
void compute() | |
{ | |
# pragma omp parallel for num_threads(40) | |
for (int t = 0; t < 40; ++t) | |
{ | |
int tmp_bin[256] = {}; | |
for (int i = t; i < ARRSZ; i += 40) | |
{ | |
int c = arr[i]; | |
++tmp_bin[c]; | |
} | |
for (int j = 0; j < 256; ++j) | |
{ | |
int a = tmp_bin[j]; | |
# pragma omp atomic | |
bin[j] += a; | |
} | |
} | |
} |
优化:200ms
原因:每个线程创建了一个临时的桶,以固定的步长处理元素。注意到 i += 40 ,每个线程在调用时实际上也是取邻近的一大块内存区域,但是只用到了 1 个元素却丢掉了其他元素,造成访存的浪费。
void compute() | |
{ | |
int blk = (ARRSZ + 39) / 40; | |
# pragma omp parallel for num_threads(40) | |
for (int t = 0; t < 40; ++t) | |
{ | |
int tmp_bin[256] = {}; | |
int l = blk * t, r = blk * (t + 1); | |
if (r > ARRSZ) r = ARRSZ; | |
for (int i = l; i < r; ++i) | |
{ | |
int c = arr[i]; | |
++tmp_bin[c]; | |
} | |
for (int j = 0; j < 256; ++j) | |
{ | |
int a = tmp_bin[j]; | |
# pragma omp atomic | |
bin[j] += a; | |
} | |
} | |
} |
优化:45ms
原因:每个线程处理一块连续内存区域的数据。
# GPU
// naive cuda | |
__global__ void histogram_kernel_v1(unsigned char *array, unsigned int *bins) | |
{ | |
int tid = blockIdx.x * blockDim.x + threadIdx.x; | |
// We do not need to check boundary here as ARRSZ is a power of 2. | |
atomicAdd(&bins[array[tid]], 1u); | |
} | |
void compute() | |
{ | |
const int block_size = 256; | |
histogram_kernel_v1<<<ARRSZ / block_size, block_size>>>(arr_gpu, bin_gpu); | |
assert(cudaSuccess == cudaDeviceSynchronize()) | |
} |
未优化:213ms
// naive cuda + unroll | |
__global__ void histogram_kernel_v2(unsigned char *array, unsigned int *bins) | |
{ | |
int tid = blockIdx.x * blockDim.x + threadIdx.x; | |
unsigned int value_u32 = array[tid]; | |
atomicAdd(&bins[value_u32 & 0x000000FF], 1u); | |
atomicAdd(&bins[(value_u32 & 0x0000FF00) >> 8], 1u); | |
atomicAdd(&bins[(value_u32 & 0x00FF0000) >> 16], 1u); | |
atomicAdd(&bins[(value_u32 & 0xFF000000) >> 24], 1u); | |
} | |
void compute() | |
{ | |
const int block_size = 256; | |
histogram_kernel_v2<<<ARRSZ / block_size / 4, block_size>>>((unsigned int *)arr_gpu, bin_gpu); | |
assert(cudaSuccess == cudaDeviceSynchronize()); | |
} |
优化循环展开:200ms,
原因:atomic 带来的竞争问题并没有得到解决。
// naive cuda + shared memory | |
__shared__ unsigned int bins_shared[256]; | |
__global__ void histogram_kernel_v3(unsigned char *array, unsigned int *bins) | |
{ | |
int tid = blockIdx.x * blockDim.x + threadIdx.x; | |
bins_shared[threadIdx.x] = 0; // block size assumed to be just 256 | |
__syncthreads(); //gpu 中所有运行的 thread 同时暂停(我的理解是等待所有 thread 执行完当前指令) | |
unsigned int value_u32 = array[tid]; | |
atomicAdd(&bins_shared[value_u32 & 0x000000FF], 1u); | |
atomicAdd(&bins_shared[(value_u32 & 0x0000FF00) >> 8], 1u); | |
atomicAdd(&bins_shared[(value_u32 & 0x00FF0000) >> 16], 1u); | |
atomicAdd(&bins_shared[(value_u32 & 0xFF000000) >> 24], 1u); | |
__syncthreads(); | |
atomicAdd(&bins[threadIdx.x], bins_shared[threadIdx.x]); | |
} | |
void compute() | |
{ | |
const int block_size = 256; | |
histogram_kernel_v3<<<ARRSZ / block_size / 4, block_size>>>((unsigned int *)arr_gpu, bin_gpu); | |
assert(cudaSuccess == cudaDeviceSynchronize()); | |
} |
优化共享内存:9ms
原因:由于 bin 的大小是 256,所以每个 block 开 256 个线程, atomicAdd(&bins[threadIdx.x], bins_shared[threadIdx.x]); 一句就能将 bin 中的所有数据都写进去。这里不做循环展开的话也是 9ms。
//naive cuda + shared memory + more unroll: N = 32 * 4, fat kernel, interleave (fixed step, 交错) | |
__shared__ unsigned int bins_shared[256]; | |
const int N = 32; | |
__global__ void histogram_kernel_v4(unsigned char *array, unsigned int *bins) | |
{ | |
int toffset = blockIdx.x * blockDim.x + threadIdx.x; | |
int sz = gridDim.x * blockDim.x // thread size in a grid. gridDim.x: block size; blockDim.x: thread size in one block. | |
bins_shared[threadIdx.x] = 0; // block size assumed to be just 256 | |
__syncthreads(); //gpu 中所有运行的 thread 同时暂停(我的理解是等待所有 thread 执行完当前指令) | |
for (int i = 0, tid = toffset; i < N; ++i, tid += sz) | |
{ | |
unsigned int value_u32 = array[tid]; | |
atomicAdd(&bins_shared[value_u32 & 0x000000FF], 1u); | |
atomicAdd(&bins_shared[(value_u32 & 0x0000FF00) >> 8], 1u); | |
atomicAdd(&bins_shared[(value_u32 & 0x00FF0000) >> 16], 1u); | |
atomicAdd(&bins_shared[(value_u32 & 0xFF000000) >> 24], 1u); | |
} | |
__syncthreads(); | |
atomicAdd(&bins[threadIdx.x], bins_shared[threadIdx.x]); | |
} | |
void compute() | |
{ | |
const int block_size = 256; | |
histogram_kernel_v4<<<ARRSZ / block_size / 4 / N, block_size>>>((unsigned int *)arr_gpu, bin_gpu); | |
assert(cudaSuccess == cudaDeviceSynchronize()); | |
} |
优化共享内存 + 更多的循环展开:<1ms
原因:让一个 kernel 干更多的事情,去抵消 launch kernel 的开销。
//naive cuda + shared memory + contiguous unroll: N = 32 * 4, fat kernel, interleave (fixed step, 交错) | |
__shared__ unsigned int bins_shared[256]; | |
const int N = 32; | |
__global__ void histogram_kernel_v4_5(unsigned char *array, unsigned int *bins) | |
{ | |
int i = blockIdx.x * blockDim.x + threadIdx.x; | |
bins_shared[threadIdx.x] = 0; // block size assumed to be just 256 | |
__syncthreads(); //gpu 中所有运行的 thread 同时暂停(我的理解是等待所有 thread 执行完当前指令) | |
int l = i * N, r = (i + 1) * N; | |
for (tid = l; tid < r; ++tid) | |
{ | |
unsigned int value_u32 = array[tid]; | |
atomicAdd(&bins_shared[value_u32 & 0x000000FF], 1u); | |
atomicAdd(&bins_shared[(value_u32 & 0x0000FF00) >> 8], 1u); | |
atomicAdd(&bins_shared[(value_u32 & 0x00FF0000) >> 16], 1u); | |
atomicAdd(&bins_shared[(value_u32 & 0xFF000000) >> 24], 1u); | |
} | |
__syncthreads(); | |
atomicAdd(&bins[threadIdx.x], bins_shared[threadIdx.x]); | |
} | |
void compute() | |
{ | |
const int block_size = 256; | |
histogram_kernel_v4_5<<<ARRSZ / block_size / 4 / N, block_size>>>((unsigned int *)arr_gpu, bin_gpu); | |
assert(cudaSuccess == cudaDeviceSynchronize()); | |
} |
优化共享内存 + 更多的循环展开,且临近:2ms
原因:interleave 下每次循环取 块数据。contiguous 下每次循环取 块数据,会给软件不可见的 Cache 或显存带来压力。
# Debug a GPU Program
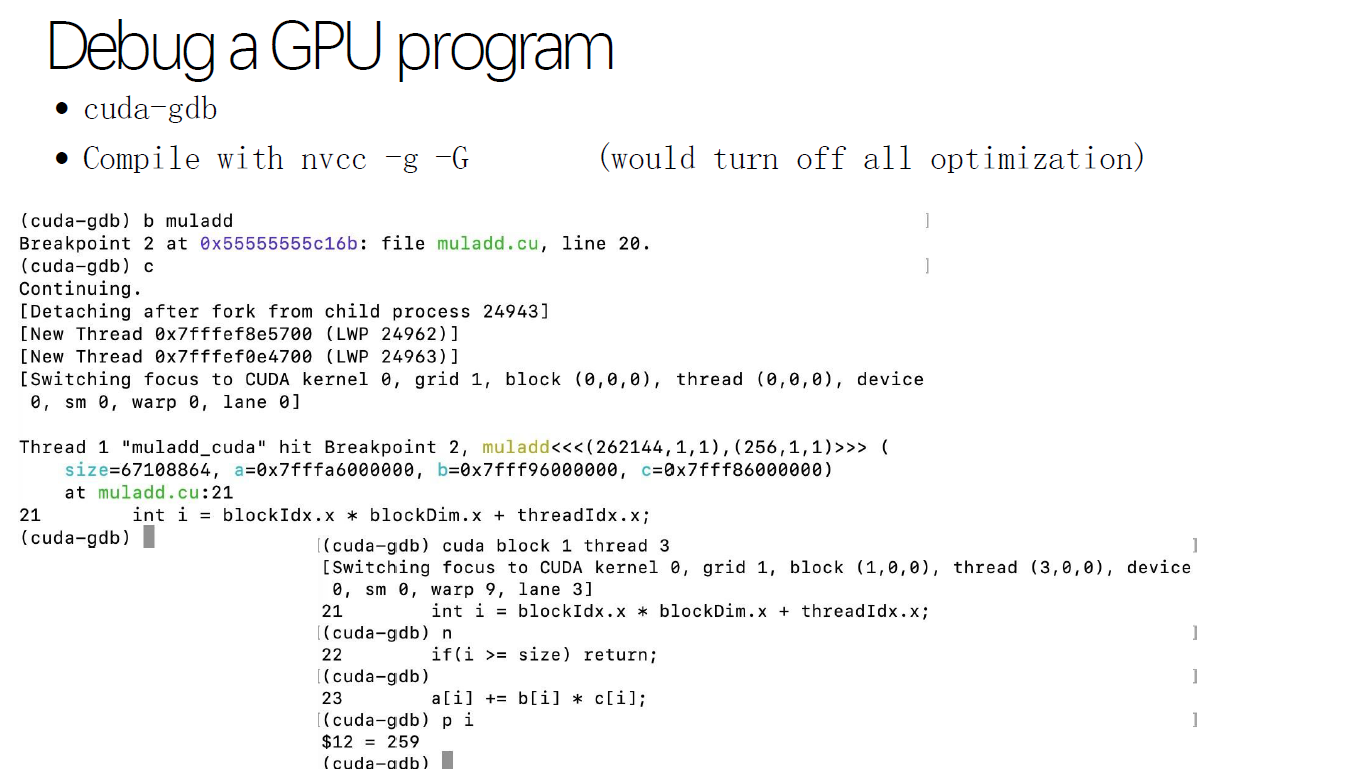
一个常见的调试 pattern:写一个 CPU kernel 和一个 GPU kernel,发现某个位置算错了,算出来是在 cuda block 1 thread 3 算错了,直接通过 cuda-gdb 查看这里为什么算错了。