# 基本工具
# SSH
创建公私钥
ssh-keygen |
将本地公钥和私钥上传到服务器:
# 方法 1 | |
ssh-copy-id -i ~/.ssh/id_rsa.pub <server> | |
# 方法 2 | |
cat ~/.ssh/id_rsa.pub | ssh <server> 'cat >> ~/.ssh/authorized_keys' |
# RSYNC
能够同步更新两处计算机的文件与目录,并适当利用差分编码以减少数据传输量。——Wikipedia
基本用法:
# rsync [option] source destination 同步的策略是将目标地址中没有但源地址有的文件同步 | |
rsync A B | |
rsync -r A B # 递归同步,如果 A 是个文件夹就会递归同步 A 下的所有内容 | |
rsync -a A B # 递归同步的同时同步元信息,比如文件权限 | |
rsync --delete A B # 在同步过程中删除只存在于 B 而不存在于 A 的内容(相当于让目标 B 和源 A 保持一致) | |
# A 和 B 都可以是远程的地址 | |
# example: guojunyi@dl1:/home/guojunyi/B |
# 开发工具
# SISD vs SIMD vs SIMT
- SISD:单个指令操作单个数据。exp:a [i] + b [i]
- SIMD:单个指令操作多个数据。exp: a [i-i+4] + b [i-i+4]
- SIMT:单个指令调用多个线程。单个指令会调用不同的硬件进行计算。
# SIMD: AVX/SSE
高级向量扩展指令集(Advanced Vector Extensions, AVX)是 x86 架构微处理器中的指令集。——Wikipedia
# 一个例子
// SISD | |
vectorAdd(float* a, float* b, float* c) | |
{ | |
for (int i = 0; i < 8; i++) | |
{ | |
c[i] = a[i] + b[i]; | |
} | |
} |
float 4 字节占用 32bit,长度为 8 的 float 数组一共是 256bit。
// SIMD | |
__m256 vectorAdd(__m256 a, __m256 b, __m256 c) | |
{ | |
return _mm256_add_ps(a, b); | |
} |
在 AVX 指令集中,使用上述指令可以一次性返回 256bit 数据的加和。但代价是需要先将原有的存放 8 个 float 数据的数组转化成对应的 256bit 向量。
# 优点和缺点
- 更高速的计算方法
- 更高的开发复杂度
- 更复杂的 CPU 架构
# SIMT: CUDA/ROCM
CUDA (Compute Unified Device Architecture, 统一计算架构) 是由 NVIDIA 推出的一种集成技术,是其对 GPGPU (General Propose Graphic Processing Unit,通用目的的图形处理器) 的正式名称。
ROCm 是 AMD (Advanced Micro Devic) 的软件栈,用于 GPU 编程。——Wikipedia
// CUDA | |
__global__ void addVector(float* a, float* b, float* c) | |
{ | |
int tid = blockIdx.x; | |
if (tid < 8) | |
c[tid] = a[tid] + b[tid]; | |
} |
上述程序会启动多个并行的流程同时操作。每个流程中拿到的 tid 是不同的。
# SIMT:OPENCL
OpenCL (Open Computing Language,开放计算语言) 是一个为异构平台编写程序的框架,此异构平台可由 CPU、GPU、DSP、FPGA 或其他类型的处理器与硬体加速器构成。——Wikipedia
__kernel void vector_add(float* a, global const float* b, global float* c) | |
{ | |
int gid = get_global_id(0); | |
if (gid < 8) | |
c[tid] = a[tid] + b[tid]; | |
} |
# MULTI-THREAD: OPENMP
OpenMP 是一套支持跨平台共享内存方式的多线程并发的编程 API。——Wikipedia
为了利用多线程,我们可以使用一些更底层的库进行开发(如 Linux 下可以使用 pthread),OpenMP 提供了一种更统一、简洁且跨平台的方式进行开发。
// OpenMP | |
vectorAdd(float* a, float* b, float* c) | |
{ | |
# pragma omp for | |
for (int i = 0; i < 8; i++) | |
{ | |
c[i] = a[i] + b[i]; | |
} | |
} |
# 性能调优
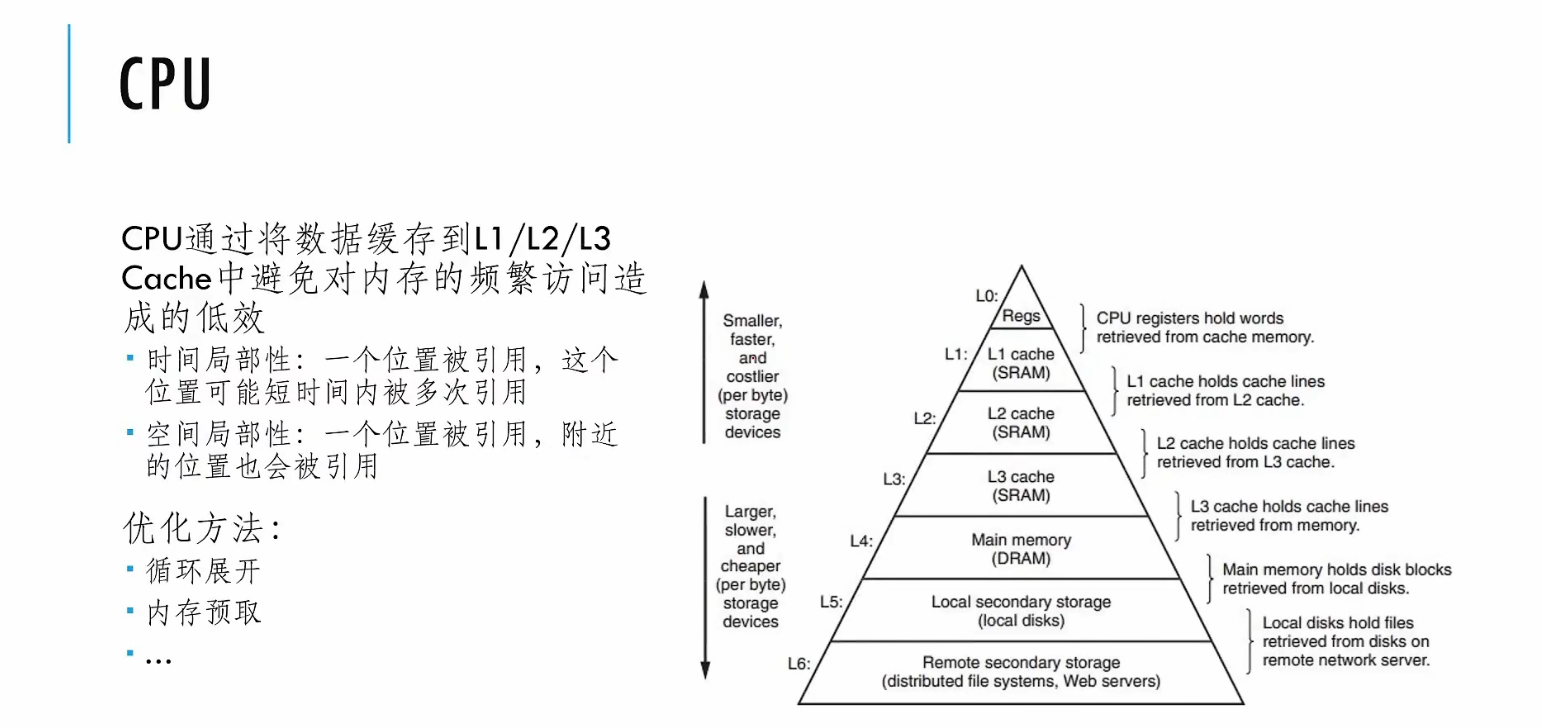
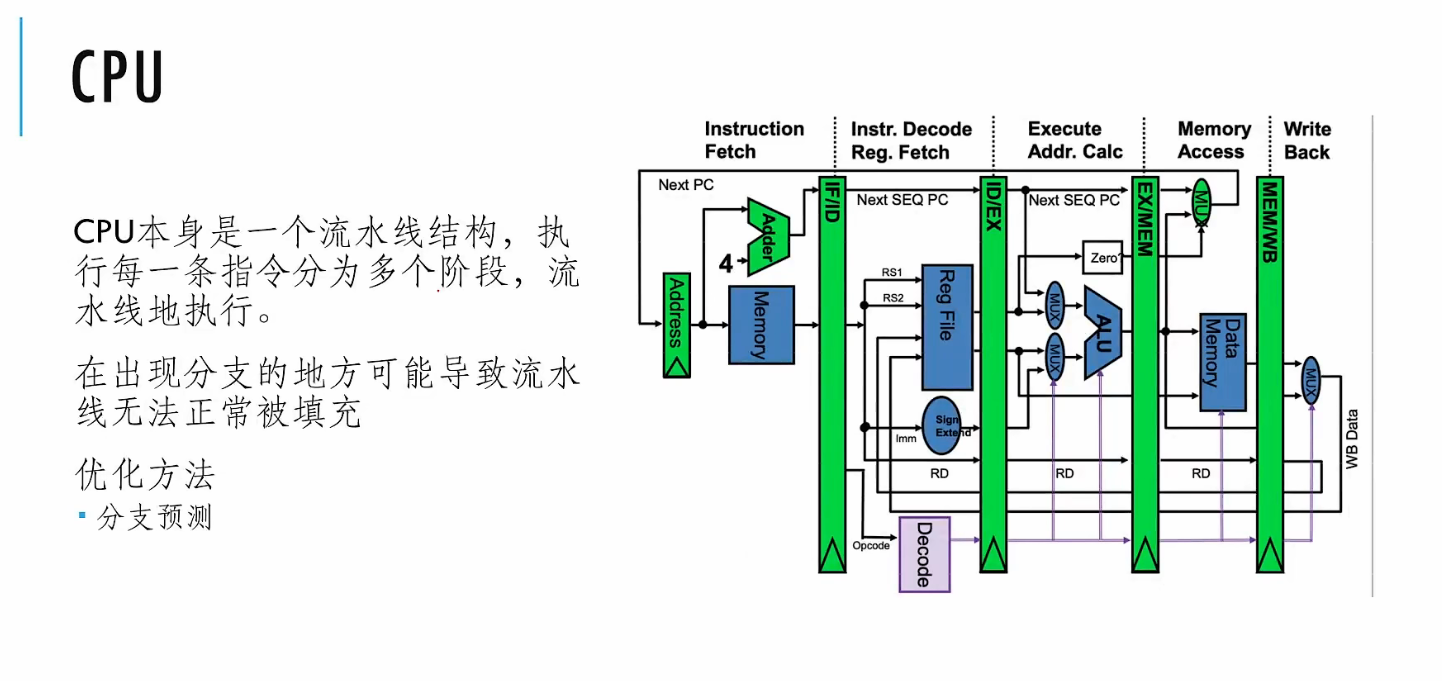
# CPU
// CPP20 | |
if (n > 0) [[likely]] | |
{ | |
// ... | |
} | |
else [[unlikely]] | |
{ | |
// ... | |
} |
# GPU
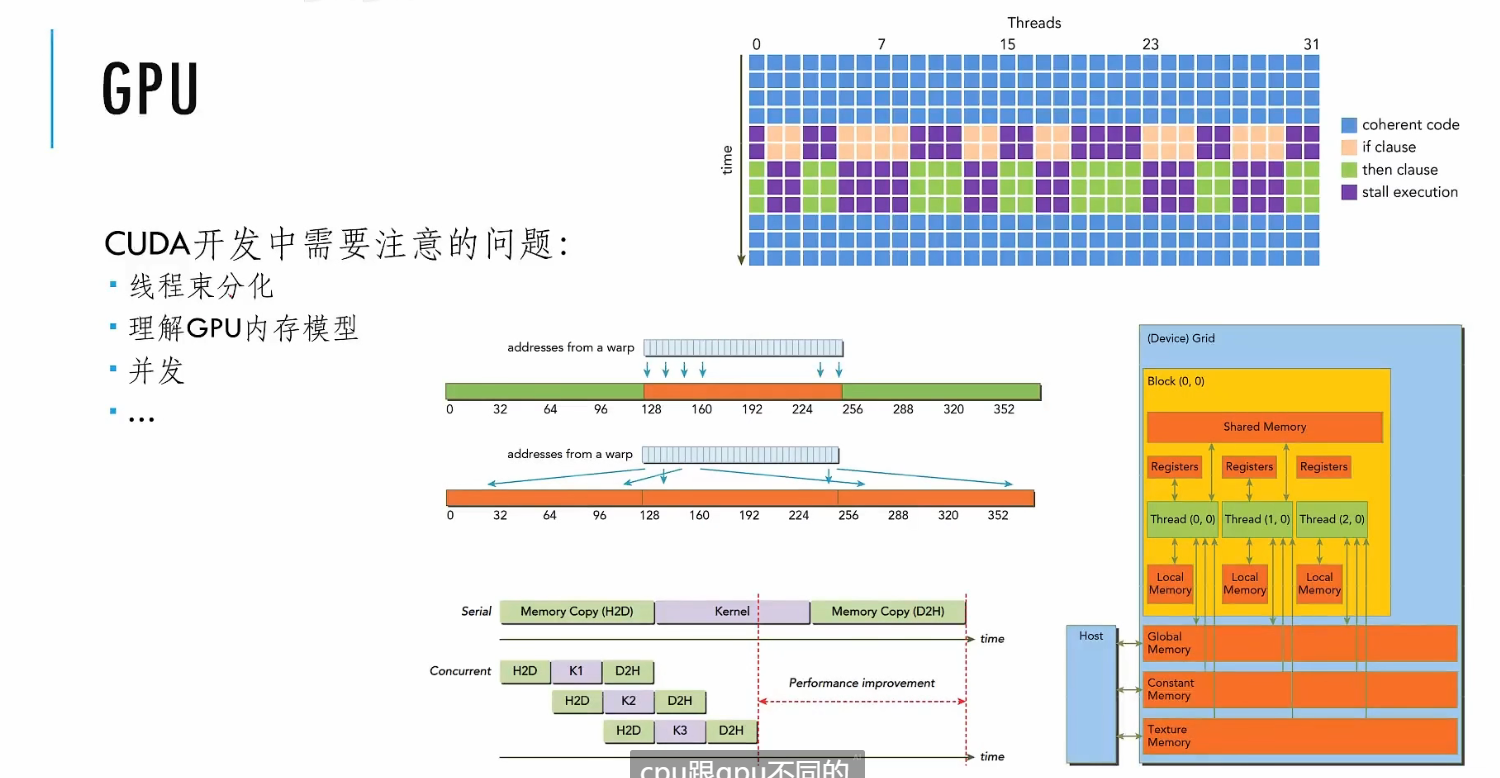
一些补充:
- 线程束分化
- GPU 内存模型:GPU 有多种不同的内存(global memory, constant memory, texture memory),如果访问的数据在多个不同内存中,一次性无法读完所有需要的数据,这会极大浪费 GPU 的带宽。在单个线程束访存时(假设每个线程访问不同的数组),相比于传统的存储方式(每个数组拥有连续的存储区域),
a[0]b[0]c[0]d[0]这样的存储方式对 GPU 的执行会更有效率。 - 并发:首先将数据拷贝到 GPU 中,随后启动 GPU 上的进程执行内容,最后再将数据拷贝回 CPU(从 GPU 的片上内存拷贝回主存),如果完整地经历这个步骤实际上十分低效。可以将每一个步骤分成三份,拷贝完一部分数据就进行处理,同时进行下一部分数据的拷贝(流水线化),这样可以提高效率。
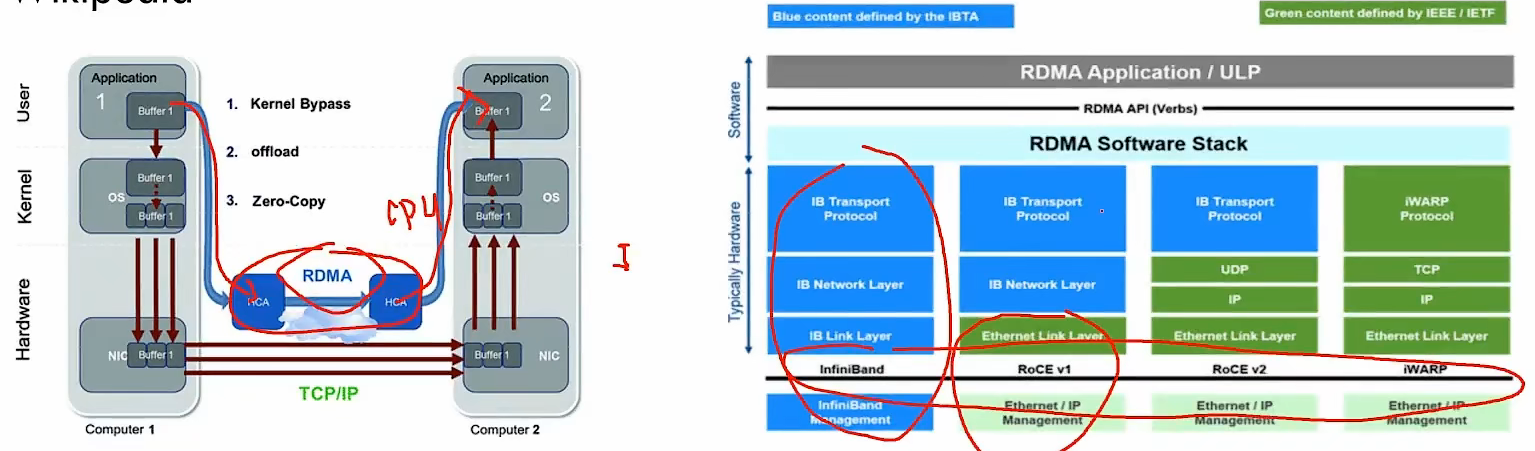
# RDMA
在数据中心领域,远程直接内存访问(Remote Direct Memory Access, RDMA)是一种绕过远程主机操作系统内核访问其内存中数据的技术,由于不经过操作系统,不仅节省了大量 CPU 资源,同时也提高了系统吞吐量、降低了系统网络通信延迟,尤其适合在大规模并行计算机集群中有广泛应用。——Wikipedia